Las Pequeñas y Medianas Empresas
(PyMES) dedicadas al desarrollo de software o que cuentan con un área o unidad
de negocio dedicadas a ello, están generando una parte significativa del
software utilizado en el mundo. Sin embargo, carecen de una metodología de
desarrollo de software son adaptados; y en casos extremos, ni siquiera son
utilizados.
¿Cómo elegir la metodología de desarrollo de software
“adecuada a utilizar” en proyectos de producción de software?

Gráfica 1. Modelo propuesto por Barry Boehm y Richard Turner.
El modelo propuesto por Barry
Boehm y Richard Turner es un modelo de fácil comprensión capaz de evaluar
cuantificar e identificar 5 variables críticas a la hora de decidir si el
desarrollo de un sistema se aventura por metodologías ágiles o robustas.
Personal. El por ciento del personal con capacidad, experiencia y
posibilidades para enfrentar tareas es un aspecto de mucha importancia en un
proyecto de producción de software, de esto depende mucho la posibilidad que
tiene el grupo de desarrolladores de poder implantar o desarrollar un tipo de
metodología u otra. Esta variable tiene su mayor importancia a la hora de
adoptar métodos ágiles que requieren de un personal con niveles de experiencia
medios-altos, capaces de comprender y adaptar los métodos y las técnicas
empleadas.
Criticidad. La criticidad del sistema resultada determinante cuando se
habla de proyectos cuya falla puede traer pérdidas de vidas humanas, daño al
medio ambiente y grandes pérdidas económicas, por lo que se hace necesario
emplear métodos robustos capaces de mantener un rigor de requisitos y diseño
adecuados para procesos de pruebas, verificación y validación.
Cultura. El por ciento del personal con capacidad para enfrentarse a
entornos caóticos resulta importante a la hora de adoptar métodos ágiles los
cuales se basan fundamentalmente en el talento de las personas, un ambiente
laboral con un control excesivamente normalizado y jerarquizado resultaría
incómodo para llevar a cabo este tipo de práctica.
Tamaño La cantidad de personas de un proyecto resulta importante en dependencia
de qué método ágil o robusto se vaya a poner en práctica. Para métodos ágiles
donde es muy significativa una buena comunicación entre todos los integrantes
del grupo de desarrollo esta resulta imposible con un número alto de personal
en el proyecto.
Dinamismo. El por ciento de cambios de requerimientos que pueden
ocurrir en un mes tiene gran peso en los métodos ágiles preparados para
enfrentar este tipo de situación, resultaría muy incómodo enfrentar grandes
cambios de requerimientos con métodos robustos que tienen grandes volúmenes de
documentación y una verificación y validación de procesos continua.
Tiempo.
El tiempo de respuesta requerido por
el cliente para obtener su producto resulta determinante a la hora de escoger
una metodología, para proyectos que se necesiten terminar en un periodo de
tiempo breve resultaría tedioso seleccionar un método robusto estos se ajustan
más a sistemas a largo plazo con un gran número de requerimientos.
¿Por qué adicionar la
variable Tiempo de respuesta requerido por el cliente al Modelo de Barry
Boehm y Richard Turner ?
En la actualidad el tiempo de respuesta requerido por el
cliente es un factor muy importante a tener en cuenta a la hora de desarrollar
un software y seleccionar una metodología de desarrollo. Resulta determinante
cumplir con el tiempo que requiere el cliente, de lo contrario esto podría
traer consigo consecuencias desfavorables para el proyecto en cuanto a su costo
su tiempo de desarrollo, errores en la aplicación entre otros. La relación
entre los beneficios y la cantidad de tiempo necesario para poner el producto o
servicios en el mercado tiene gran significado, cuanto menor sea el tiempo o
plazo para llegar al mercado mayor serán los beneficios. Esto posibilita que se
pueda alcanzar a diferentes tipos de usuarios y consumidores. A medida que
transcurre el tiempo se incrementan los costos, se desmotiva el personal,
aumenta la presión y existen mayores posibilidades de perder personal
involucrado en el desarrollo.adecuada a
sus necesidades y sus recursos, ya que las metodologías existentes y sus marcos
de trabajo difícilmente.
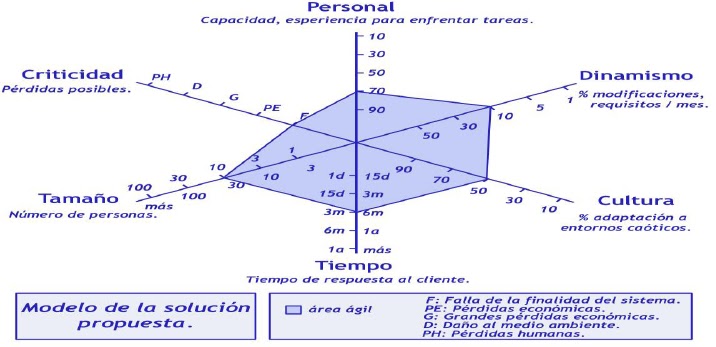
Gráfica 2. Delimita el área ágil.

Gráfica 3. Delimita el área formal.